इमर्सिव ऑडियो–वीडियो यथार्थवाद
मोशन स्थिरता और भौतिक रूप से प्रशंसनीय गति, नेटिव ऑडियो संकेतों के साथ — समीक्षा कैमरा मूल के करीब लगे।
टेक्स्ट / इमेज / ऑडियो / वीडियो एकीकृत कंडीशनिंग के लिए नई पीढ़ी का मॉडल — निर्देशक की तरह ब्रीफ: कंपोज़िशन लॉक करें, मोशन नियंत्रित करें, छोटे प्रॉम्प्ट डेल्टा से पुनरावृत्ति।
प्रॉम्प्ट पहले भरें, अनुपात और अवधि सेट करें, एक क्लिक में वर्कस्पेस खोलें।
टीमें आज मल्टीमॉडल वीडियो कैसे ब्रीफ करती हैं — व्यावहारिक सारांश।
उत्पाद कथा एकीकृत मल्टीमॉडल पथ पर केंद्रित है: स्थिर टाइमबेस, अधिक विश्वसनीय भौतिकी, और चित्र के साथ ताल में ऑडियो — बाद में चिपकाया नहीं। LimaxAI में वर्कस्पेस के नियंत्रणों से शॉट-दर-शॉट काम करें: मॉडल, अनुपात, अवधि, संदर्भ और टियर के अनुसार वैकल्पिक ऑडियो।
वास्तविक डिलीवरी के लिए पिच — स्पेक शीट नहीं।
मोशन स्थिरता और भौतिक रूप से प्रशंसनीय गति, नेटिव ऑडियो संकेतों के साथ — समीक्षा कैमरा मूल के करीब लगे।
प्रॉम्प्ट और संदर्भ — इमेज, ऑडियो या छोटे क्लिप जहाँ समर्थित — प्रदर्शन, प्रकाश और लेंस व्याकरण बिना पूरा ब्रीफ दोबारा लिखे।
आउटपुट विज्ञापन, सोशल और प्रीविज़ के लिए प्लेट — टाइमलाइन पर काट, ग्रेड और बदलने योग्य छोटे लूप।
LimaxAI वर्कस्पेस में दिखने वाले नियंत्रणों से मेल।
पहले फ्रेम या संदर्भ इमेज से कंपोज़िशन लॉक — मोशन संश्लेषण से पहले प्रोडक्ट हीरो, पोर्ट्रेट और ब्रांड लेआउट।
शुद्ध वीडियो कंडीशनिंग न हो तो मजबूत कैमरा क्रियाएँ और स्टिल संदर्भ से जटिल पथ अनुमानित करें।
प्रत्येक जनरेशन को मॉड्यूलर शॉट मानें — टाइमलाइन पर सिलें, छोटे प्रॉम्प्ट डेल्टा से पुनरावृत्ति।
LimaxAI साफ़ एक्सपोर्ट के लिए — मास्क, कट और ऑडियो आपके सामान्य टूलचेन में।
डिलीवरी समीक्षा में दिखने वाली सात शक्तियाँ। सीमाएँ प्लान और कतार पर निर्भर।
ग्रेडिंग हेडरूम वाले उच्च-निष्ठा फ्रेम — विशेषकर लंबे शॉट जहाँ शोर आता था।
सक्षम होने पर संवाद / ambience इरादे को चित्र से जोड़ें ताकि कटों के बीच मुँह और कमरा कम बहें।
प्रॉम्प्ट को बीट (स्थापना → पुश → पेऑफ़) में संरचित करें ताकि छोटे क्लिप में इरादा बचे।
वर्कस्पेस में अनुमत संदर्भों के साथ टेक्स्ट — स्टिल, समर्थित मॉडल पर वैकल्पिक ऑडियो फ़्लैग और Seedance 2.0 पर omni सूचियाँ।
वेरिएंट में एक ही हीरो चाहिए तो अपरिवर्तनीय (वस्त्र, लोगो ज्यामिति, पैलेट) दोहराएँ।
गुरुत्व, संपर्क और तरल गति पूर्ण गति पर सही — विशेषकर प्रोडक्ट और हैंडहेल्ड।
साफ कमर्शियल से स्टाइलाइज़्ड फिक्शन — पूर्ण पुनर्लेखन के बजाय संकीर्ण प्रॉम्प्ट संपादन।
सामान्य उत्पाद टियर में त्वरित अवलोकन। SKU के साथ आँकड़े बदलते हैं — डिलीवरी योजना लॉक करने से पहले प्रत्येक कंसोल और LimaxAI में सत्यापित करें।
| क्षमता | Seedance 2.0 | Sora 2 (OpenAI) | Veo 3 (Google) | Kling 2.6 (Kwai) |
|---|---|---|---|---|
| अधिकतम क्लिप लंबाई (सामान्य उपभोक्ता टियर) | सामान्य टियर पर ~15s तकअग्रणी | ~15s (उच्च टियर लंबा उल्लेख) | ~8s सामान्य | ~10s सामान्य |
| मल्टीमॉडल संदर्भ | एक स्टैक में टेक्स्ट / इमेज / ऑडियो / वीडियो संदर्भअग्रणी | सीमित / विकसित हो रहा | टेक्स्ट + इमेज सामान्य पथ | टेक्स्ट + इमेज सामान्य पथ |
| मल्टी-बीट कहानी | मजबूत नेटिव मल्टी-बीट फ्रेमिंगअग्रणी | तृतीय-पक्ष तुलना में कमज़ोर | अक्सर एकल-बीट | अक्सर एकल-बीट |
| ऑडियो–वीडियो सिंक | संयुक्त ऑडियो–वीडियो जनरेशन पथअग्रणी | अक्सर आंशिक | अक्सर समर्थित | क्लिप प्रकार के अनुसार भिन्न |
| कैरेक्टर / प्रोडक्ट स्थिरता | लंबे टेक में मजबूत पहचान निरंतरताअग्रणी | फ़्लैगशिप डेमो में मजबूत | फ़्लैगशिप डेमो में ठोस | फ़्लैगशिप डेमो में मजबूत |
| भौतिकी प्रशंसनीयता | मजबूत बेंचमार्क कथाबराबर | फ़्लैगशिप डेमो में मजबूत | फ़्लैगशिप डेमो में ठोस | फ़्लैगशिप डेमो में मजबूत |
| उद्धृत सामान्य डिलीवरी रिज़ॉल्यूशन | सामग्री में अक्सर 1080p / 2K उल्लेखअग्रणी | 1080p सामान्य | कुछ टियर पर 4K तक | 1080p सामान्य |
*सामान्य मार्केटिंग-टियर पोज़िशनिंग; रिज़ॉल्यूशन, अवधि और मोडैलिटी उत्पाद अपडेट के साथ बदलती हैं।
मल्टीमॉडल ट्रिक्स के अलावा, जनरेशन स्टैक को बेस-मॉडल लिफ्ट के रूप में पिच किया जाता है: अधिक विश्वसनीय भौतिकी, साफ मोशन व्याकरण, कड़ा निर्देश पालन और शांत स्टाइल ड्रिफ्ट। जब ब्रीफ सामग्री, लेंस और गति नाम दे तो लंबे टेक, संपर्क-भरे एक्शन और प्रोडक्ट रोटेशन कम 「लॉटरी」 लगते हैं।
टेक्स्ट और संदर्भ से नियंत्रित करें — लेआउट के लिए स्टिल, मोशन व्याकरण के लिए छोटे क्लिप, स्टैक अनुमति दे तो लय के लिए ऑडियो। तेज़ प्रॉम्प्ट संदर्भ के साथ जोड़ें ताकि जो नहीं हिलना चाहिए लॉक हो — पूरे स्क्रिप्ट नहीं, बीट पुनरावृत्ति। क्या संलग्न कर सकते हैं LimaxAI प्लान और सक्रिय मॉडल पर निर्भर।
चेहरे बहना, लेबल धुंधला होना, माइक्रो-टाइप गिरना और टोन कूदना — समीक्षक पहले यही कहते हैं। 2.0 कथा शॉटों में पहचान, वस्त्र और प्रॉप्स थामने पर जोर देती है — फिर NLE में मास्क और संपादन।
संदर्भ-प्रथम: इमेज से लुक, क्लिप से मोशन व्याकरण, कुछ सेकंड ऑडियो से लय — फिर प्रॉम्प्ट से कसें ताकि पुनरावृत्ति निर्देशन जैसी लगे, जुआ नहीं।
चेहरे, वस्त्र, टाइप और प्रॉप्स शॉटों में करीब रहते हैं — पिकअप पर कम आश्चर्यजनक री-रोल।
वीडियो संदर्भ समर्थित हो तो जटिल ब्लॉकिंग के लिए; अन्यथा क्रियाएँ और स्टिल संदर्भ।
संदर्भ और कड़े प्रॉम्प्ट डेल्टा से विज्ञापन बीट, स्टाइल ट्रांज़िशन और सिनेमैटिक सजावट।
ब्रीफ में अपरिवर्तनीय स्पष्ट रखें, मॉडल बीच के बीट प्रस्तावित करे।
उत्पाद पथ समर्थन करे तो चिकना विस्तार — अन्यथा प्लेट एक्सपोर्ट और संपादकीय सिलाई।
ऑडियो-जागरूक टियर पर अधिक प्राकृतिक टिम्बर और साफ़ संवाद।
एक मूव में कम हार्ड कट — वॉकथ्रू और परफॉर्मेंस शॉट के लिए।
इन-मॉडल संपादन विक्रेता अनुसार; LimaxAI ऑफ़लाइन सर्जिकल पैच के लिए साफ़ एक्सपोर्ट पर केंद्रित।
ऑडियो संदर्भ उपलब्ध हों तो मोशन को बीट और ambience से मिलाएँ।
माइक्रो-एक्सप्रेशन और ब्लॉकिंग नैरेटिव और प्रेज़ेंटर क्लिप में मजबूत।
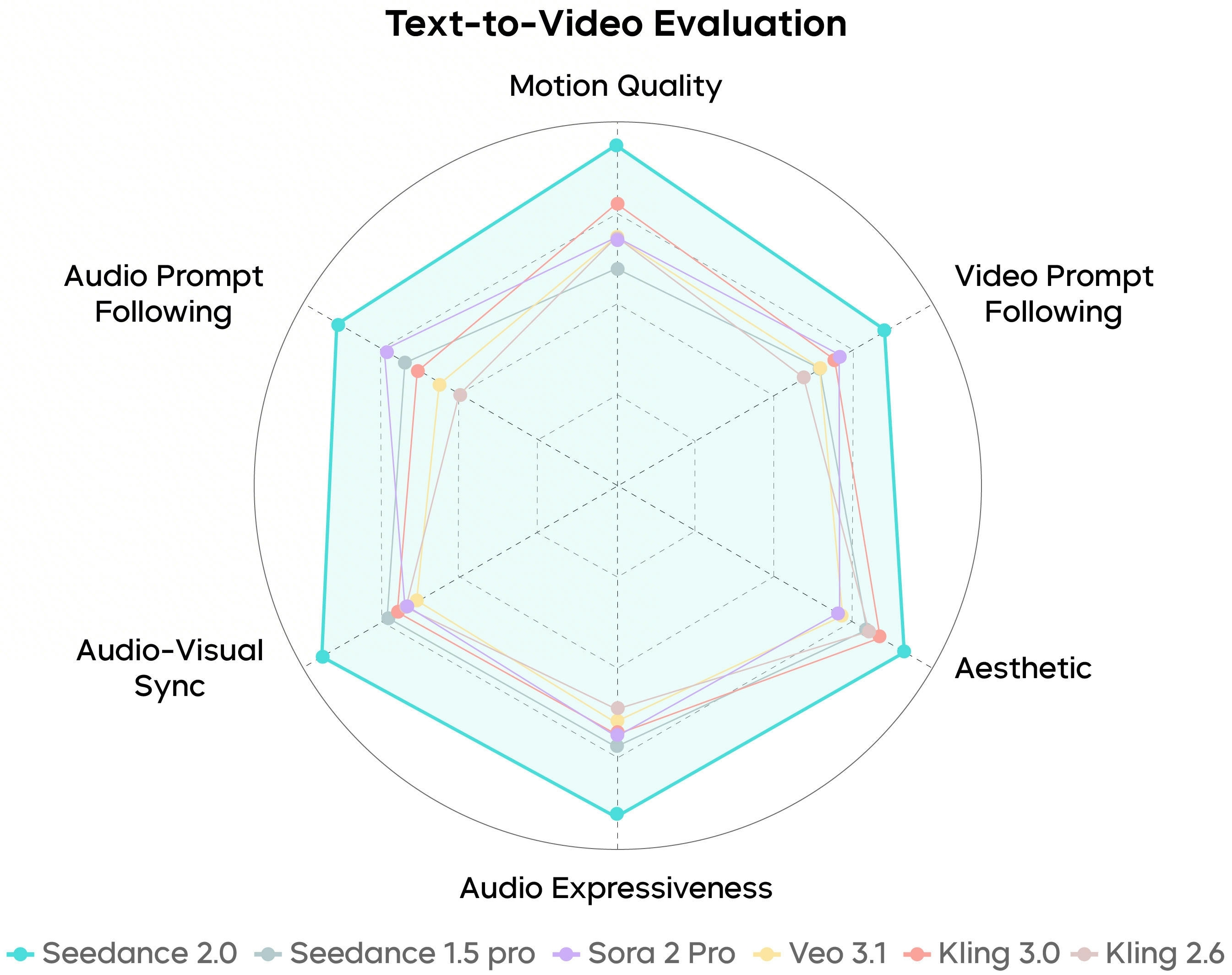
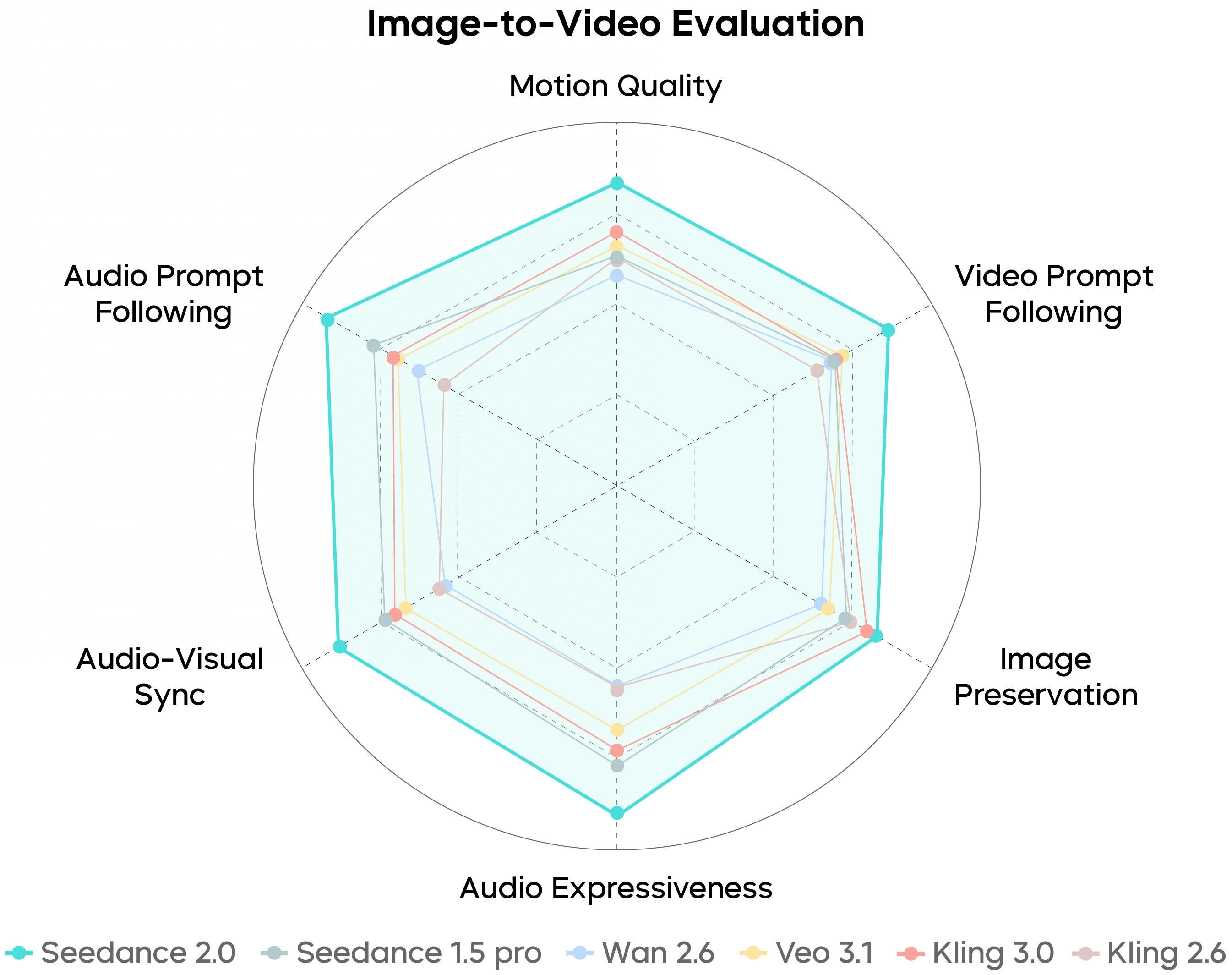
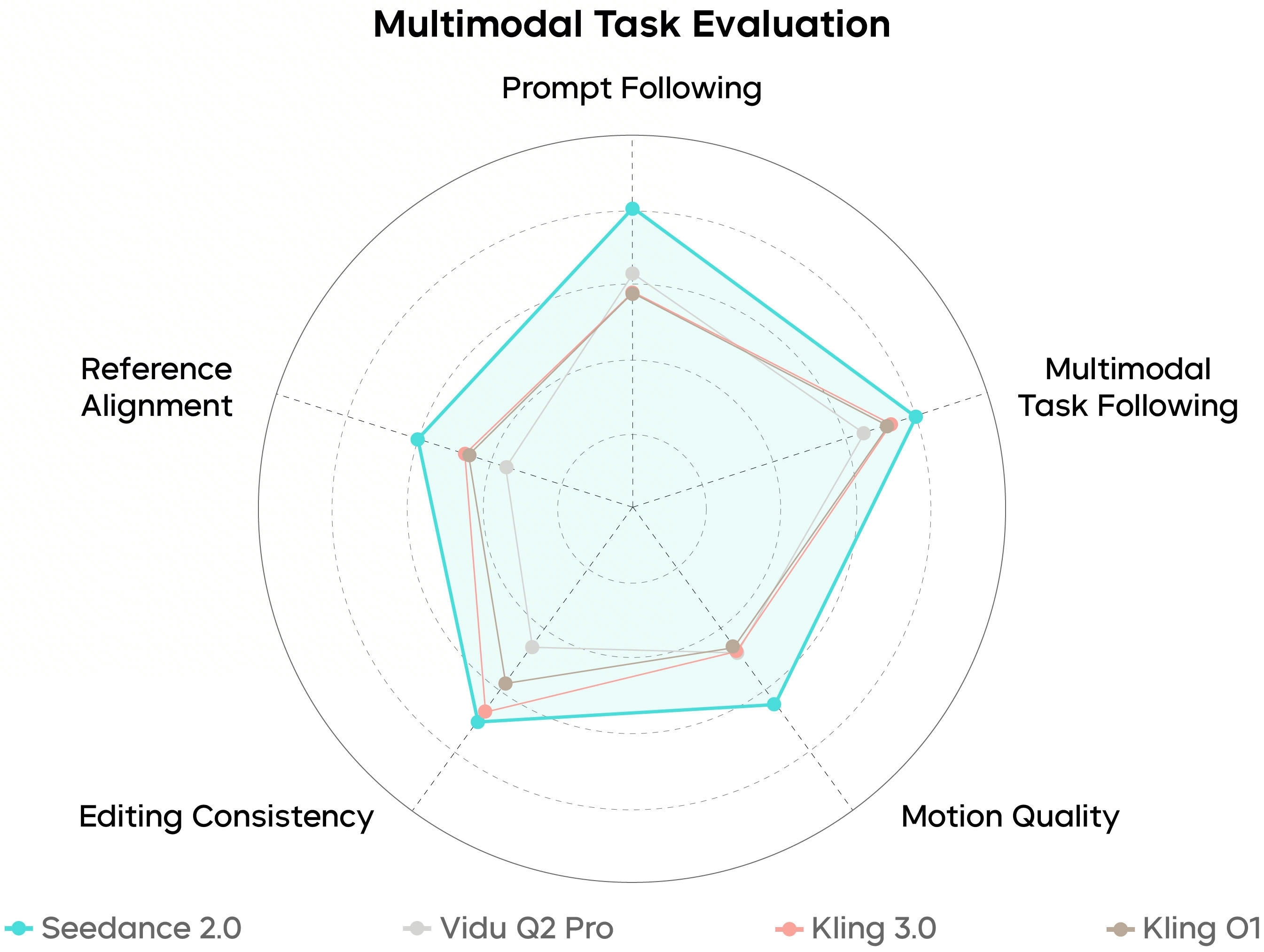
SeedVideoBench-2.0 बताता है Seedance 2.0 text-to-video, image-to-video और मल्टीमॉडल पर कैसे मूल्यांकित होता है — मोशन, प्रॉम्प्ट पालन, सौंदर्य और ऑडियो।
बेंचमार्क दिशात्मक हैं: आपके प्रॉम्प्ट, संदर्भ और प्लान टियर अभी भी टाइमलाइन पर क्या जाता है तय करते हैं।
Seedance 2.0
एकीकृत ऑडियो–वीडियो पथ: स्थिर भौतिकी, स्पष्ट निर्देश पालन और समृद्ध संदर्भ मोड — रचनात्मक इरादा पहले कट में बचे, सिर्फ पहले फ्रेम में नहीं।
LimaxAI वीडियो वर्कस्पेस खोलेंVeo लैंडिंग जैसे चौड़े हीरो डेमो — एक समय में एक केंद्रित क्लिप — समीक्षक मोशन पर निर्णय लें।
समीक्षा में दिखने वाले तीन डेल्टा — सिर्फ मार्केटिंग स्लाइड में नहीं।
फ्रेमों में कम आकृति बदलाव; पहचान योग्य चेहरे, प्रोडक्ट और लोगो के लिए बेहतर।
सामान्य गति पर सही गुरुत्व, संपर्क और पैरालैक्स संकेत।
लेंस, गति और बीट सादी भाषा में — फिर पूर्ण पुनर्लेखन के बजाय छोटे डेल्टा से पुनरावृत्ति।
सामान्य डिलीवरी अनुरोध: मैक्रो विवरण, टेबलटॉप ASMR ऊर्जा, हैंडहेल्ड वॉकथ्रू।
हीरो ऑब्जेक्ट लॉक करें, सामग्री तीक्ष्ण रखें, कैमरा बिना धुंधले विवरण के चले।
ज़ूम QC पास के लिए नियंत्रित परावर्तन और एज स्थिरता।
कैमरा ड्रिफ्ट पर भी सुसंगत पैरालैक्स और गहराई — इंटीरियर और लाइफस्टाइल के लिए।
अगला विचार जगाने के लिए हमारा क्यूरेटेड शोकेस देखें।
संदर्भ-प्रथम वर्कफ़्लो, टेम्पोरल स्थिरता, भौतिकी और निर्देश पालन — प्रोमो, सोशल कट और प्रोडक्ट डेमो ब्रीफ के अनुरूप।
पहले रंग पास में टिकने वाली प्लेट: स्किन टोन, सामग्री और स्पेक्युलर अनुशासन।
फ्रेमों में कम आकस्मिक विकृति — चेहरे, लोगो और हीरो प्रोडक्ट जो कैमरा चलते भी पहचाने जाएँ।
पाइपलाइन अनुमति दे तो प्रॉम्प्ट को इमेज, ऑडियो या छोटे संदर्भ क्लिप से जोड़ें — लेंस व्याकरण और गति ब्रीफ में बचें।
प्रॉम्प्ट से शुरू करें, स्टिल से लेआउट एंकर करें, या पुनरावृत्ति में स्टाइल और मोशन के लिए मल्टीमॉडल संदर्भ।
डिलीवरी के लिए महत्वपूर्ण: इनपुट, रिज़ॉल्यूशन, अनुपात और पाइपलाइन नोट — संपादन और वितरण से मिलाएँ।
मॉडल
Seedance 2.0
LimaxAI पर नवीनतम पीढ़ी का वीडियो मॉडल, निरंतर सुधार।
जनरेशन गति
तेज़ पुनरावृत्ति
गति और गुणवत्ता संतुलित वीडियो स्टैक; समय लंबाई, रिज़ॉल्यूशन और कतार पर निर्भर।
इनपुट
टेक्स्ट या पहला-फ्रेम इमेज
शुद्ध प्रॉम्प्ट या अपलोड फ्रेम — मोशन से पहले लेआउट और पहचान एंकर।
आउटपुट रिज़ॉल्यूशन
HD वीडियो
पेशेवर समीक्षा और सोशल डिलीवरी के लिए उच्च-परिभाषा एक्सपोर्ट।
कैमरा नियंत्रण
प्रॉम्प्ट योग्य मूव
पैन, टिल्ट, पुश और हैंडहेल्ड ऊर्जा सीधे प्रॉम्प्ट में लिखें।
पहलू अनुपात
लैंडस्केप और पोर्ट्रेट प्रीसेट
वेब, विज्ञापन और शॉर्ट-फ़ॉर्म फ़ीड के लिए सामान्य 16:9 और 9:16 प्रीसेट।
शॉट को ब्रीफ जैसे लिखें, अवधि और अनुपात चुनें, टाइमलाइन पर डालने योग्य क्लिप एक्सपोर्ट करें।
वातावरण, विषय, मोशन, मूड और कैमरा क्रियाएँ (वाइड एस्टैब्लिशिंग, धीमा पुश-इन)। लॉक कंपोज़िशन के लिए पहला फ्रेम जोड़ें।
गंतव्य चैनल से मिलाएँ — फ़ीड के लिए वर्टिकल, वेब के लिए हॉरिज़ॉन्टल — फिर गुणवत्ता प्रीसेट से लागत बनाम स्थिरता।
टाइमलाइन मानसिक मॉडल पर तेज़ स्क्रब: मोशन और कंपोज़िशन जाँचें, फिर संपादन, VO और फिनिशिंग के लिए साफ़ फ़ाइल एक्सपोर्ट।
पूर्ण प्रोडक्शन कैलेंडर के बिना भरोसेमंद मोशन और तीक्ष्ण इमेजरी चाहने वाली टीम और क्रिएटर।
प्रकाशन गति बनाए रखने के लिए मजबूत बी-रोल और कॉन्सेप्ट शॉट।
शूट दिन के बिना प्रोडक्ट एक्सप्लेनर और कैंपेन विज़ुअल।
कई कोण और हुक आज़माते हुए दृश्य भाषा सुसंगत रखें।
महंगे कैप्चर से पहले सिनेमैटिक और ट्रेलर बीट प्रोटोटाइप।
सेटिंग और जटिलता के अनुसार कई सेकंड से दर्जनों सेकंड के क्लिप। प्रत्येक रन को संपादन के मॉड्यूलर शॉट मानें, एक पास में पूरी फ़िल्म नहीं।
सोशल, पिच और आंतरिक समीक्षा के लिए HD-स्तर आउटपुट। डिलीवरी लक्ष्य से मेल खाता टियर चुनें।
पहला फ्रेम अपलोड करें; मॉडल संभावित निरंतरता अनुमानित करता है ताकि मोशन लेआउट और विषय से जुड़ा लगे।
हाँ, LimaxAI शर्तों और लागू मॉडल नीतियों के अधीन। बड़े अभियानों से पहले विनियमित उद्योगों में अनुपालन सत्यापित करें।
प्रकाश, सामग्री, कैमरा व्याकरण और गति विशिष्ट रखें। हर बार सब कुछ दोबारा लिखने के बजाय छोटे प्रॉम्प्ट डेल्टा से पुनरावृत्ति करें।
नहीं। LimaxAI स्वतंत्र उत्पाद है। क्षमताएँ, कोटा और शर्तें आपके समझौते और इन-प्रोडक्ट सेटिंग का अनुसरण करती हैं।
LimaxAI एक स्वतंत्र उत्पाद है। मॉडल सुविधाएँ, कोटा और शर्तें आपके समझौते और इन-प्रोडक्ट सेटिंग का अनुसरण करती हैं।
वीडियो वर्कफ़्लो
लिखित ब्रीफ को काटने योग्य क्लिप में — शेड्यूलिंग में सप्ताह न खोएँ।