Realismo audio-video immersivo
Stabilità di movimento e moto fisicamente plausibile, abbinati a cue audio nativi, così le revisioni si avvicinano agli originali camera.
Modello di nuova generazione ottimizzato per percorsi di conditioning testo / immagine / audio / video unificati—così puoi briefingare come un regista: bloccare composizione, guidare movimento e iterare con delta prompt più piccoli.
Precompila un prompt, regola rapporto e durata, poi salta al workspace con un clic.
Un ritratto pratico di come i team briefingano oggi video multimodale.
Il racconto prodotto è centrato su un percorso multimodale unificato: timebase più stabile, fisica più credibile e audio generato in sincrono con l’immagine—non incollato come ripiego. In LimaxAI lavori ripresa per ripresa con i controlli esposti nel workspace: modello, rapporto, durata, riferimenti e audio opzionale dove il tier lo supporta.
Come viene presentato il modello per delivery reale—non una scheda tecnica.
Stabilità di movimento e moto fisicamente plausibile, abbinati a cue audio nativi, così le revisioni si avvicinano agli originali camera.
Prompt più riferimenti—immagine, audio o clip brevi dove supportato—per coreografare performance, luce e grammatica ottica senza riscrivere tutto il brief ogni volta.
Output pensati come piatti per ads, social e previz—loop corti che puoi tagliare, gradare e sostituire su timeline.
Mappate sui controlli che vedrai nel workspace LimaxAI.
Blocca composizione con primo fotogramma o immagini di riferimento—utile per hero prodotto, ritratti e layout brand prima che il moto sia sintetizzato.
Quando il conditioning video puro non è disponibile, combina verbi camera forti con still di riferimento per approssimare percorsi complessi.
Tratta ogni generazione come ripresa modulare da cucire in timeline, poi itera con piccoli delta prompt.
LimaxAI ottimizza export puliti da rifinire con maschere, tagli e sweetening audio nella toolchain di sempre.
Sette punti che emergono nelle revisioni delivery. I limiti dipendono dal piano e dalla coda.
Fotogrammi più ricchi con headroom per grading—soprattutto su riprese più lunghe dove prima compariva rumore.
Dove abilitato, abbina intento dialogo / ambientazione all’immagine così bocca e tono stanza deragliano meno tra i tagli.
Struttura i prompt come battute (establish → push → payoff) così il modello preserva intento lungo una clip corta.
Combina testo con i riferimenti consentiti nel workspace—immagini still, flag audio opzionali su modelli supportati e liste omni su Seedance 2.0.
Ripeti i non negoziabili (guardaroba, geometria logo, palette) quando serve lo stesso hero tra varianti.
Gravità, contatto e fluid motion che leggono corretti a velocità di playback piena—soprattutto per prodotto e riprese handheld.
Dal commercial pulito alla fiction stilizzata—itera con edit prompt stretti invece di riscritture complete.
Orientamento rapido tra tier prodotto comuni. Le cifre cambiano con SKU vendor—verifica in ogni console e in LimaxAI prima di bloccare un piano di delivery.
| Capacità | Seedance 2.0 | Sora 2 (OpenAI) | Veo 3 (Google) | Kling 2.6 (Kwai) |
|---|---|---|---|---|
| Durata massima clip (tier consumer tipico) | Fino a ~15s su tier tipiciIn vantaggio | ~15s (tier superiori citano di più) | ~8s tipico | ~10s tipico |
| Riferimenti multimodali | Testo / immagine / audio / video in uno stackIn vantaggio | Limitato / in evoluzione | Percorso comune testo + immagine | Percorso comune testo + immagine |
| Storytelling multi-battuta | Framing multi-battuta nativo più forteIn vantaggio | Più debole in confronti di terze parti | Spesso single-beat | Spesso single-beat |
| Sincrono audio–video | Percorso generazione congiunto audio–videoIn vantaggio | Spesso parziale | Spesso supportato | Varia per tipo clip |
| Coerenza personaggio / prodotto | Persistenza identità più forte su riprese lungheIn vantaggio | Forte nelle demo flagship | Solido nelle demo flagship | Forte nelle demo flagship |
| Plausibilità fisica | Fortissimo racconto benchmarkParità | Forte nelle demo flagship | Solido nelle demo flagship | Forte nelle demo flagship |
| Risoluzione delivery tipica citata | 1080p / 2K comunemente citatiIn vantaggio | 1080p comune | Fino a 4K su alcuni tier | 1080p comune |
*Posizionamento marketing tipico; risoluzione, durata e modalità cambiano con aggiornamenti prodotto.
Oltre ad accumulare trick multimodali, lo stack generativo viene presentato come salto di modello base: fisica più credibile, grammatica di moto più pulita, migliore aderenza alle istruzioni e deriva stilistica più calma. È ciò che rende riprese lunghe, azioni ricche di contatto e rotazioni prodotto meno “lotteria” quando il brief nomina materiali, ottica e ritmo.
Puoi guidare con testo più riferimenti—still per layout, clip brevi per grammatica di moto e audio per ritmo dove lo stack lo consente. Abbina prompt nitidi a riferimenti così il modello blocca ciò che non deve muoversi mentre iteri battute, non interi copioni. Cosa puoi allegare dipende dal piano LimaxAI e dal modello attivo.
Volti che deragliano, etichette prodotto che si strisciano, micro-tipo che collassa e tono scena che salta sono i primi dolori citati dai reviewer. Il racconto 2.0 rafforza tenuta di identità, guardaroba e oggetti chiave tra riprese—poi completi maschere e montaggio nel tuo NLE.
Workflow reference-first: imposta look con immagine, grammatica di moto con clip e ritmo con pochi secondi di audio—poi stringi con prompt così l’iterazione è più regia che roulette.
Volti, guardaroba, tipo e oggetti di scena restano più vicini tra riprese—meno re-roll sorprendenti sui pickup.
Dove il video reference è supportato, appoggiati per blocking complesso; altrimenti combina verbi con still di riferimento.
Ricrea battute ad, transizioni stilizzate e flourish cinematografici con riferimenti più delta prompt stretti.
Lascia che il modello proponga battute intermedie mentre tieni espliciti i non negoziabili nel brief.
Estensioni fluide quando il percorso prodotto lo supporta—altrimenti esporta piatti e cuci in montaggio.
Timbro più naturale e letture più pulite quando i tier consapevoli dell’audio sono abilitati.
Meno tagli duri dentro un singolo movimento—meglio per walkthrough e riprese performance.
Gli edit in-model variano per vendor; LimaxAI ottimizza comunque export puliti patchabili chirurgicamente offline.
Allinea accenti di moto a beat e ambient quando sono disponibili riferimenti audio.
Micro-espressioni e blocking leggono più forte per spot narrativi e clip presenter-led.
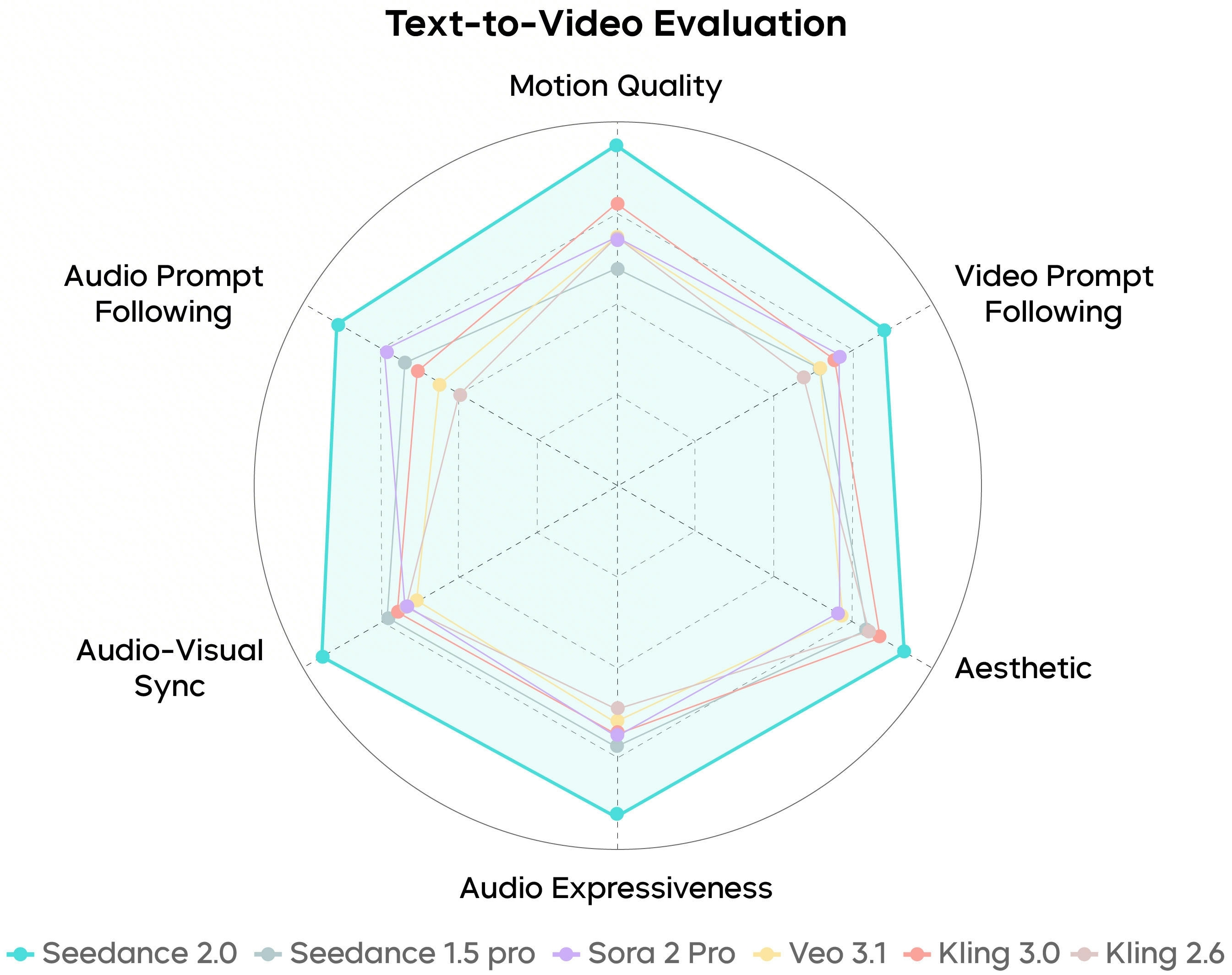
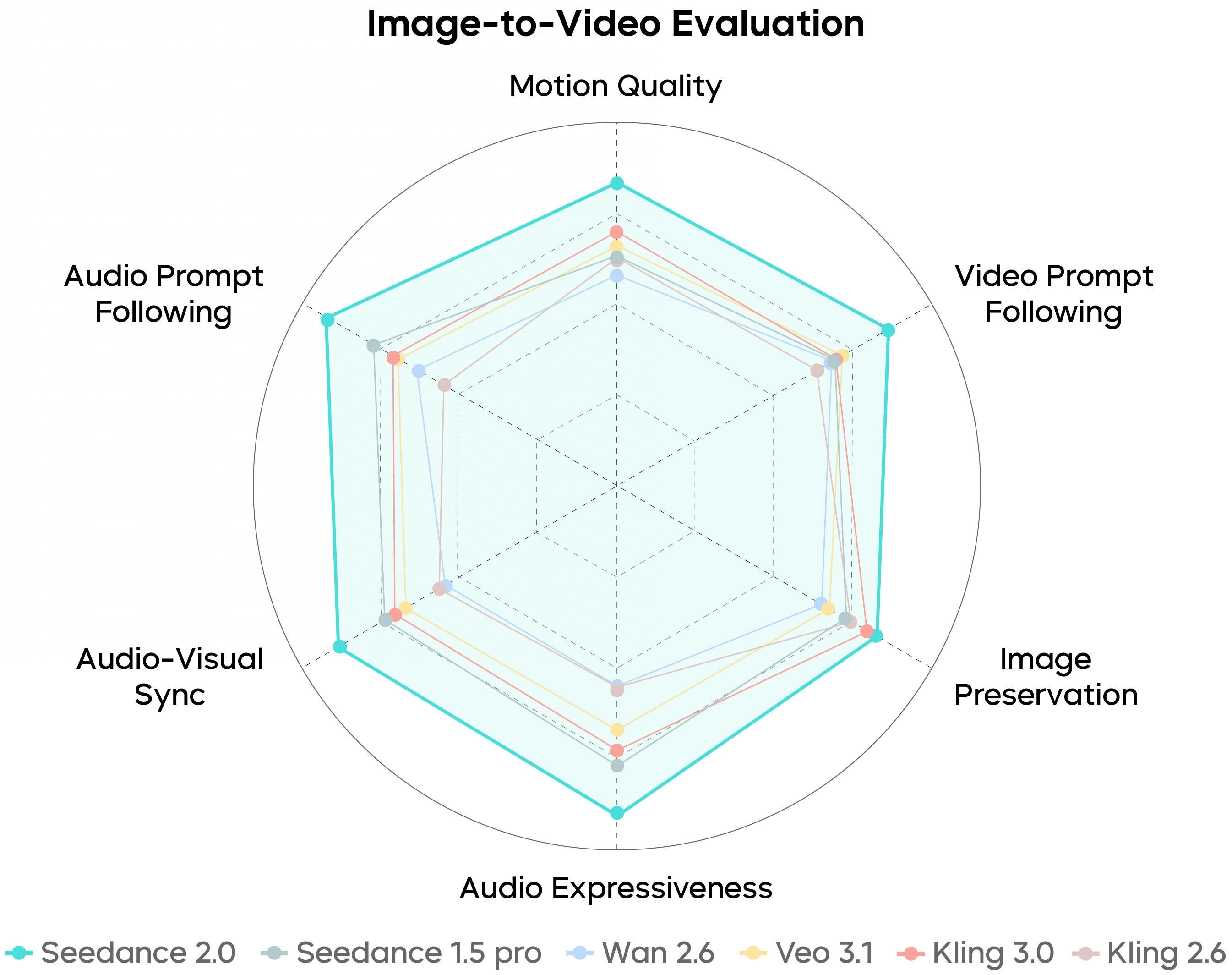
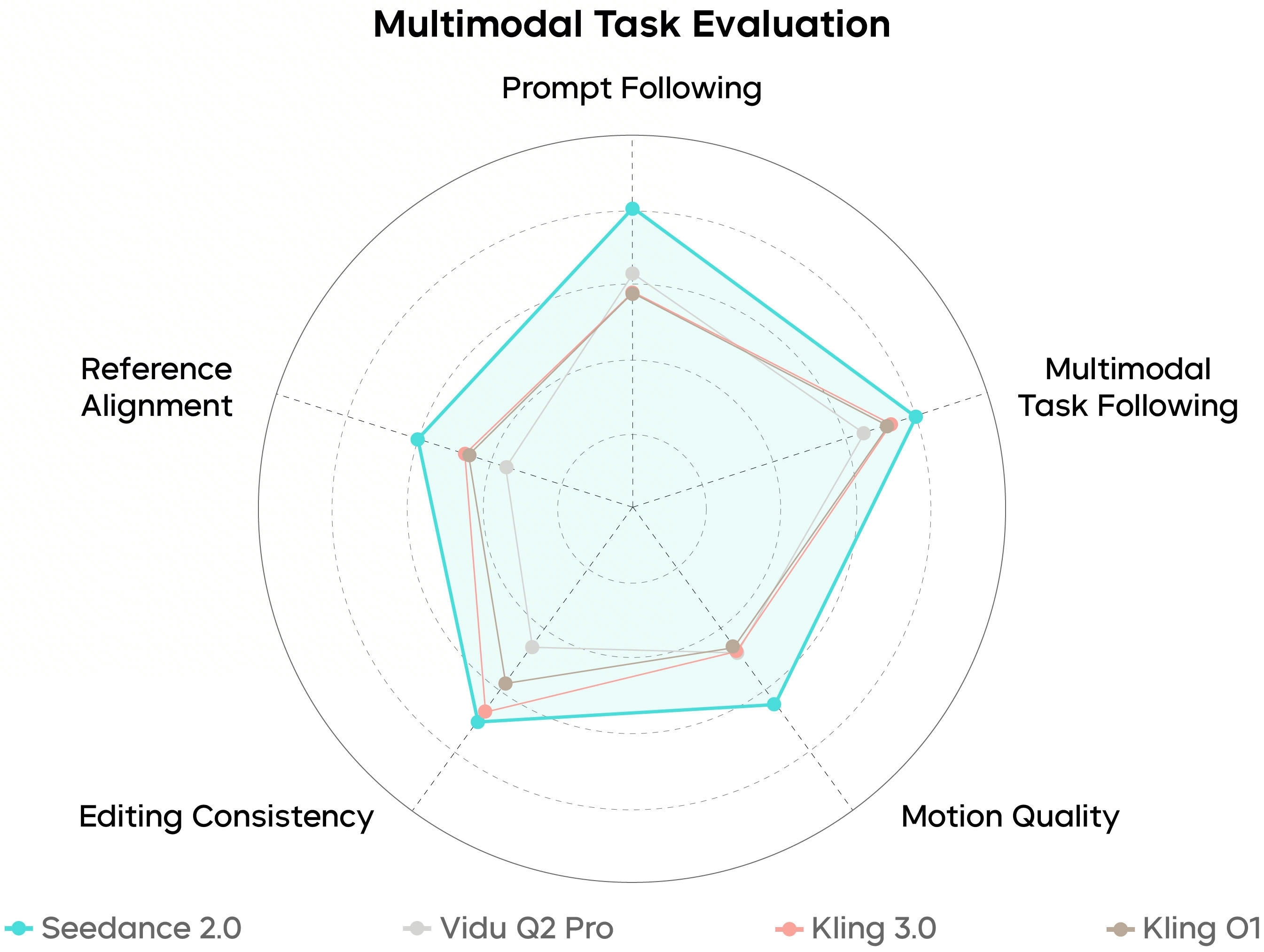
SeedVideoBench-2.0 riassume come Seedance 2.0 viene valutato su text-to-video, image-to-video e workload multimodali—qualità moto, aderenza prompt, estetica e audio sono tutti in campo.
I benchmark sono direzionali: prompt, riferimenti e tier piano decidono comunque cosa arriva in timeline.
Seedance 2.0
Percorso audio–video unificato: fisica più stabile, migliore aderenza alle istruzioni e modalità di riferimento più ricche così l’intent creativo sopravvive al primo taglio—non solo al primo fotogramma.
Apri workspace video LimaxAIHero demo ampie come la nostra landing Veo—una clip centrata alla volta—così i reviewer giudicano il moto, non le miniature.
Tre delta che emergono in revisione—non solo slide marketing.
Meno mutamenti accidentali di forma tra fotogrammi; meglio per volti, prodotti e logo che devono restare riconoscibili.
Gravità, contatto e cue parallax che leggono corretti a velocità playback normale.
Descrivi ottica, ritmo e battute in linguaggio naturale—poi itera con piccoli delta invece di riscritture complete.
Tre loop brevi che mappano richieste delivery comuni: dettaglio macro, energia ASMR da tavolo e walkthrough handheld.
Blocca oggetto hero, tieni materiali nitidi e lascia muovere la camera senza strisciare micro-dettaglio.
Riflessi controllati e stabilità dei bordi per riprese che devono reggere QC zoomato.
Parallasse e profondità coerenti mentre la camera deriva—utile per interni e lifestyle.
Sfoglia la nostra selezione per ispirare la prossima grande idea.
Workflow reference-first, stabilità temporale, plausibilità fisica e aderenza alle istruzioni—allineati a come i team briefingano promo, tagli social e demo prodotto.
Piatti che reggono primo pass colore: tonalità pelle, materiali e disciplina speculare così il grading downstream non combatte la generazione.
Meno deformazioni accidentali tra fotogrammi—utile per volti, logo e prodotti hero che devono restare riconoscibili mentre la camera si muove.
Abbina prompt a immagini, audio o clip brevi dove la pipeline lo consente—così grammatica ottica e ritmo sopravvivono alla compressione del brief.
Parti da prompt, ancora layout con uno still o appoggiati a riferimenti multimodali quando servono stile e cue di moto ripetibili tra iterazioni.
Ciò che conta per delivery: input, risoluzione, aspect ratio e note pipeline così abbini montaggio e distribuzione.
Modello
Seedance 2.0
Modello video ultima generazione su LimaxAI, in miglioramento continuo.
Velocità generazione
Iterazione rapida
Stack video ottimizzato tra velocità e qualità; tempo effettivo varia con lunghezza, risoluzione e coda.
Input
Testo o immagine primo fotogramma
Prompt puri o frame caricato per ancorare layout e identità prima che il moto sia sintetizzato.
Risoluzione output
Video HD
Export HD adatti a revisione professionale e delivery social.
Controllo camera
Mosse promptabili
Descrivi pan, tilt, push ed energia handheld direttamente nel prompt.
Aspect ratio
Preset landscape e portrait
Comuni 16:9 e 9:16 allineati a web, ads e feed short-form.
Scrivi la ripresa come brief, scegli durata e aspect, esporta una clip da buttare in timeline.
Copri ambiente, soggetto, moto, mood e verbi camera (establishing wide, slow push-in). Aggiungi immagine primo fotogramma quando serve composizione bloccata.
Allinea al canale destinazione—verticale per feed, orizzontale per web—poi bilancia costo vs stabilità con preset qualità.
Scrub mentalmente su modello timeline: controlla moto e composizione, poi esporta file pulito per edit, VO e finishing.
Team e creator che servono moto affidabile e immagine nitida senza calendario produzione completo.
Genera b-roll solidi e concept shot per mantenere alta cadenza publishing.
Sviluppa explainers prodotto e visual campagna senza bloccare su giorno riprese.
Mantieni linguaggio visivo coerente mentre testi più angoli e hook.
Prototipa cinematic e battute trailer prima di impegnarti su capture costosa.
Puoi generare clip multi-secondo fino a decine di secondi secondo impostazioni e complessità. Tratta ogni run come ripresa modulare da montare piuttosto che film finito in un solo passaggio.
Output classe HD disponibili per social, pitch deck e revisioni interne. Scegli il tier che coincide col target di delivery.
Carica un primo fotogramma; il modello inferisce continuazione plausibile così il moto resta ancorato al layout e al soggetto.
Sì, soggetto a termini LimaxAI e policy modello applicabili. Valida compliance per industrie regolate prima di campagne large-scale.
Sii specifico su luce, materiali, grammatica camera e ritmo. Itera con piccoli delta prompt invece di riscrivere tutto ogni volta.
No. LimaxAI è un prodotto indipendente. Capacità modello, quote e termini seguono il tuo accordo e le impostazioni in-product.
LimaxAI è un prodotto indipendente. Funzionalità modello, quote e termini seguono il tuo accordo e le impostazioni in-product.
Workflow video
Trasforma un brief scritto in una clip da montare—senza perdere una settimana in scheduling.